
题目
{% raw %}
{% endraw %}
西瓜在写编译原理作业中的文法分析器的时候,通常需要检测一个单词是否在给定的单词列表里。为了提高查找和定位的速度,通常都要画出与单词列表所对应的单词查找树,其特点如下:
- 根节点不包含字母,除根节点外每一个节点都仅包含一个大写英文字母;
- 从根节点到某一节点,路径上经过的字母依次连起来所构成的字母序列,称为该节点对应的单词。单词列表中的每个词,都是该单词查找树某个节点所对应的单词;
- 在满足上述条件下,该单词查找树的节点数最少。
例:图一的单词列表对应图二的单词查找树
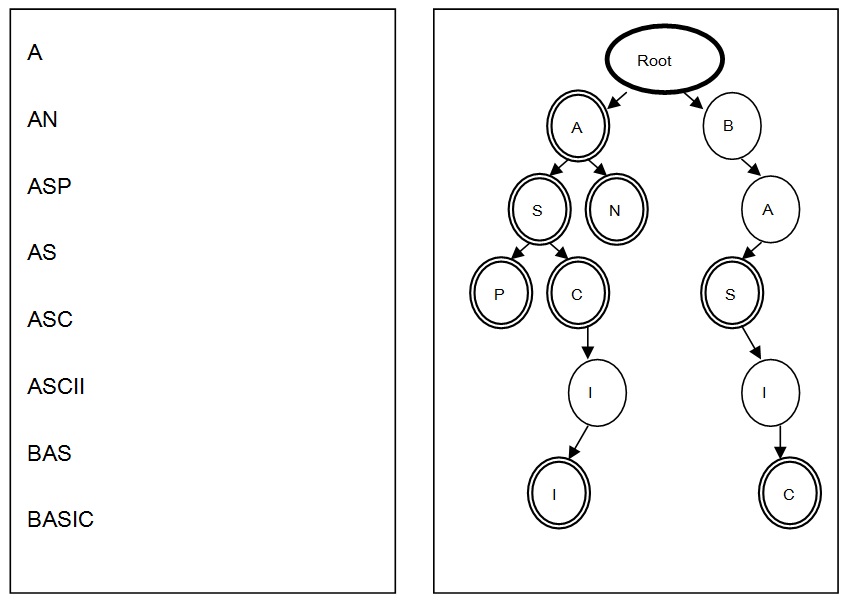

对一个确定的单词列表,请统计对应的单词查找树的节点数(包括根节点)
{% raw %}
{% endraw %}
输入一个单词列表,每一行仅包含一个单词和一个换行/回车符。每个单词仅由大写的英文字符组成,长度不超过63个字符,单词个数不超过5000。
{% raw %}
{% endraw %}
输出仅包含一个整数和一个换行/回车符。该整数为单词列表对应的单词查找树的节点数。
{% raw %}
{% endraw %}
A
AN
ASP
AS
ASC
ASCII
BAS
BASIC
{% raw %}
{% endraw %}
13
{% raw %}
题解
首先对所有字符串进行 排序

按照要求把可以合并的圈在一起,可以发现,我们要找的就是每一个字符串与前一个不同的字符及其后面所有的字符数量和加上1
这一切基于字典序天然的优势(先比较字符再比较大小)
然后计数即可
代码
```cpp 西瓜的编译原理 https://github.com/OhYee/sourcecode/tree/master/ACM 代码备份
/*/
#define debug
#include
//*/
#include
#include
#include
#include
using namespace std;
const int maxn = 5005;
string s[maxn];
int main(){
#ifdef debug
freopen("in.txt", "r", stdin);
int START = clock();
#endif
cin.tie(0);
cin.sync_with_stdio(false);
int n = 0;
while(cin >> s[n++]);
sort(s,s+n);
int ans = s[0].size();
for(int i=1;i<n;i++){
int sz = s[i].size();
for(int j=0;j<sz;j++){
if(s[i-1][j] != s[i][j]){
ans+=sz-j;
break;
}
}
}
cout << ans+1 << endl;
#ifdef debug
printf("Time:%.3fs.\n", double(clock() - START) / CLOCKS_PER_SEC);
#endif
return 0;
}
</div>

 萌ICP备20213456号
萌ICP备20213456号