分布式哈希表
分布式哈希表(Distributed Hash Table, DHT)是一项分布式的检索方式
其他分布式系统的检索方式
在分布式系统中应该如何检索数据?
在 20 世纪末与 21 世纪初,很多研究者尝试了很多方案
1999 年诞生的 Napster1 选择使用中央索引服务器,所有节点将自己拥有的文件告诉索引服务器,当有人要检索文件时,由索引服务器告诉检索者哪一个节点拥有数据,检索者就可以快速获取数据。这是一种简单高效的检索方式,但是最终 Napster 由于提供了盗版内容的检索服务而被起诉,并中止服务。这也体现了集中式的缺点:极度依赖于一个中央节点,无论是被攻击还是故障,都会导致整个网络瘫痪。
2000 年诞生的 Gnutella 使用泛洪的查询模式,每次查询都将将请求发送给自己认识的所有节点。这个过程确保了请求尽可能扩散所有节点,但是却浪费了大量的带宽(消息一传十十传百,会在网络中很快掀起一股巨浪。
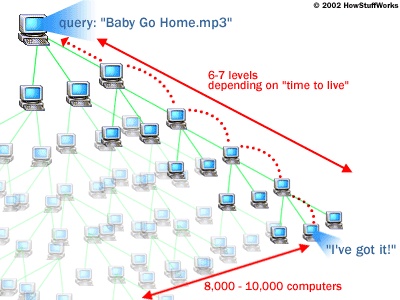 Gnutella
Gnutella当然,实际中的 Gnutella 并没有那么不堪,实际上其也有设定最大跳数和超时时间,对网络的影响是有限的。但是不得不说,这种漫无目的的请求是不明智的
Freenet 则巧妙利用文件的哈希(键)来索引文件。键本身是什么并不重要,但是确保键和文件一一对应,并且每次请求都会优先选择和键更近的节点。在找到文件后,文件会沿着请求路径返回,同时文件会被路径上所有的节点缓存。由于每次请求的路径都是与文件键相对更近的节点的键,因此文件会随着查询过程,逐渐向更更接近文件键更近的节点“移动”,最终使得查询效率更高。在这个过程中,实际上如何判断文件键和节点键的距离并不重要,只要所有的节点采用相同的方式即可。
Freenet 的方式相对于之前的技术,有了极大的进步,但是其仍然存在一个问题,对于一个检索量较低的文件,其可能距离自己应该在的节点较远,再加以请求时间和跳数的限制,以及可能存在的节点下限,即使网络中确实存在文件,也可能无法检索成功。同时 Freenet 无法做到关键字检索,因为它只能检索文件键
DHT 的原理
DHT 和 Freenet 的检索方式非常像,也是通过计算距离来实现。但在 DHT 中,由于不需要考虑 Freenet 中存在的可信节点问题,其可以直接与特定 ID 的节点通信,相对比查询效率更高
以使用 SHA-1 作为哈希算法为例,如果我们要发布一个文件,首先要计算文件的哈希值,
在这里使用 4 位的输出为例,共有 4 层二叉树,假设当前节点是 0100(图中的红色节点),其共需要存储另外的 3 个桶的部分节点,也即下图中的 1、3、4 对应的节点们,每个桶都应该维护一定量(K)的节点以供查询。下图设定 ,蓝色的节点是当前节点已经认识的节点
假设要访问编号为1001的节点,直接计算其与当前节点(0100)的距离,即可直接计算出其位于桶 4 中
因此将请求发送给位于桶 4 的邻居节点1110,并由1110进行查询
如果1110直接知道1001的节点地址,则直接发送,否则继续按照上面的办法进行查询
由于二叉树的特点,以 SHA1 160 位内容为例,只需要进行 次查询。而实际中往往 ,因此实际完全可以在更少的查询次数内获得结果
